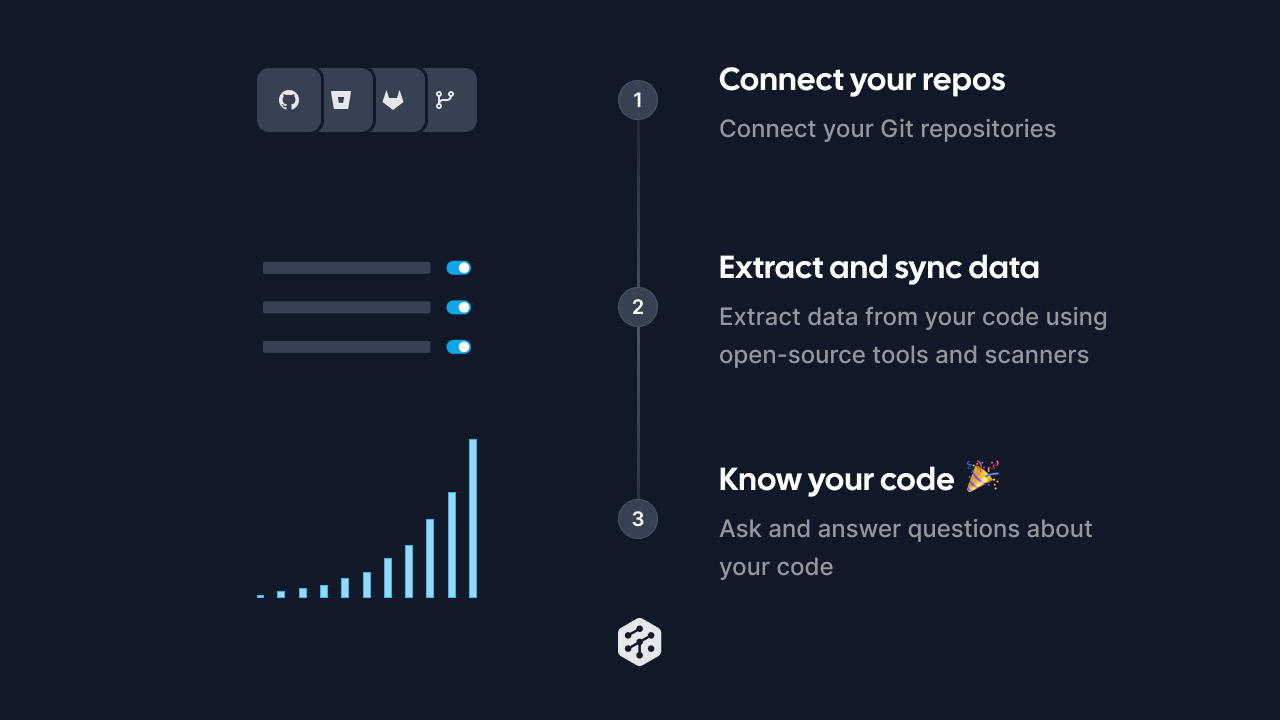
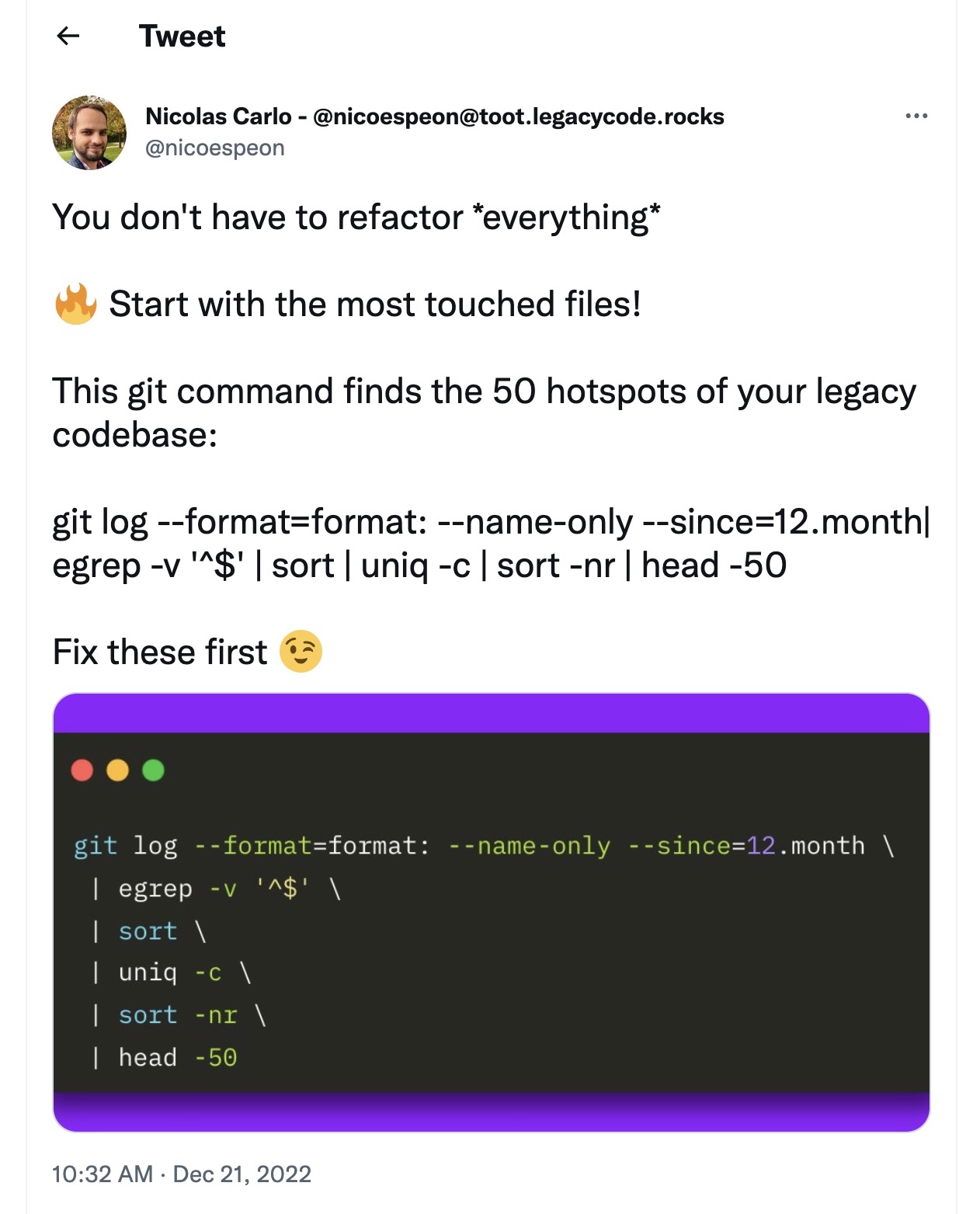
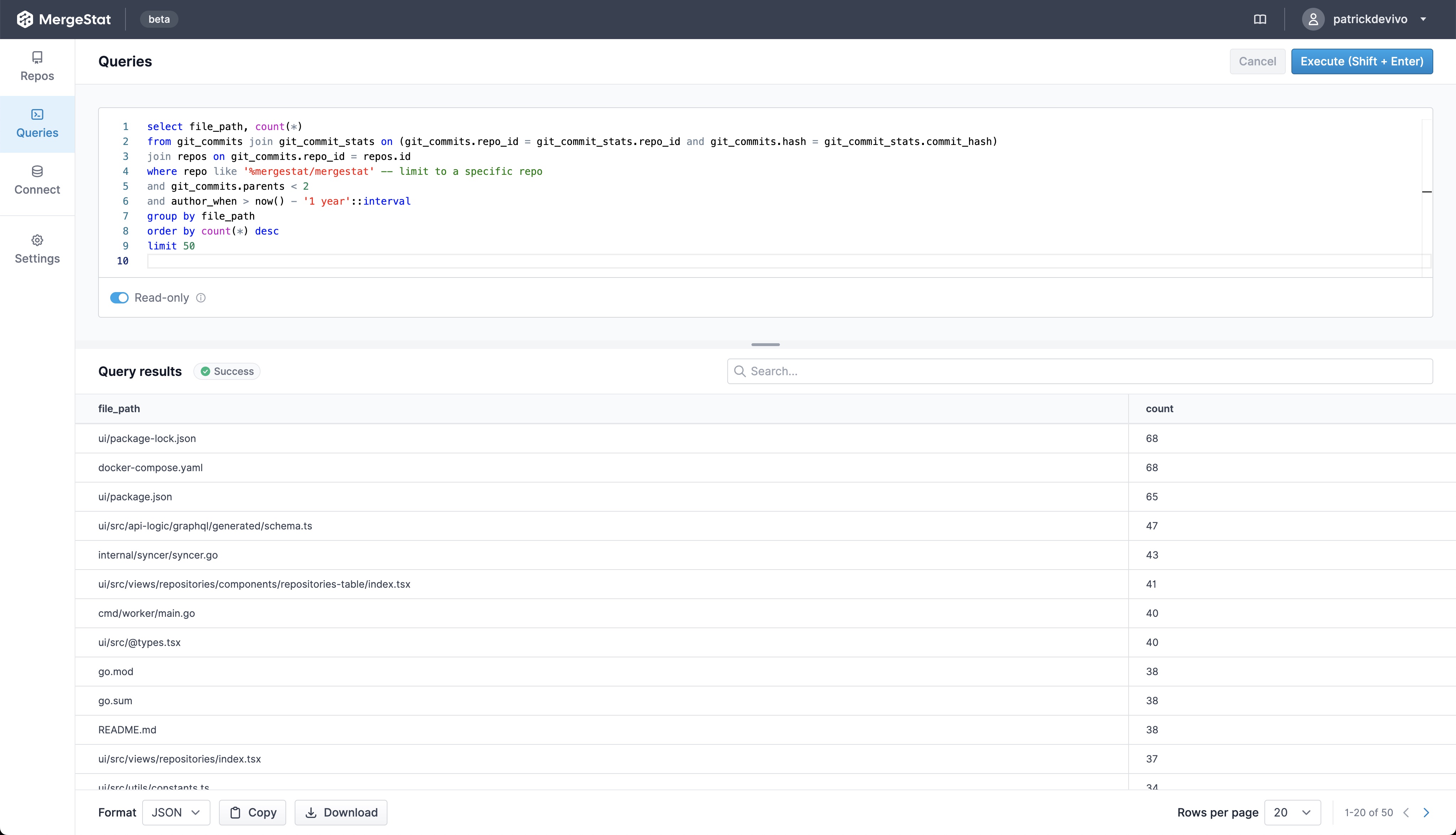
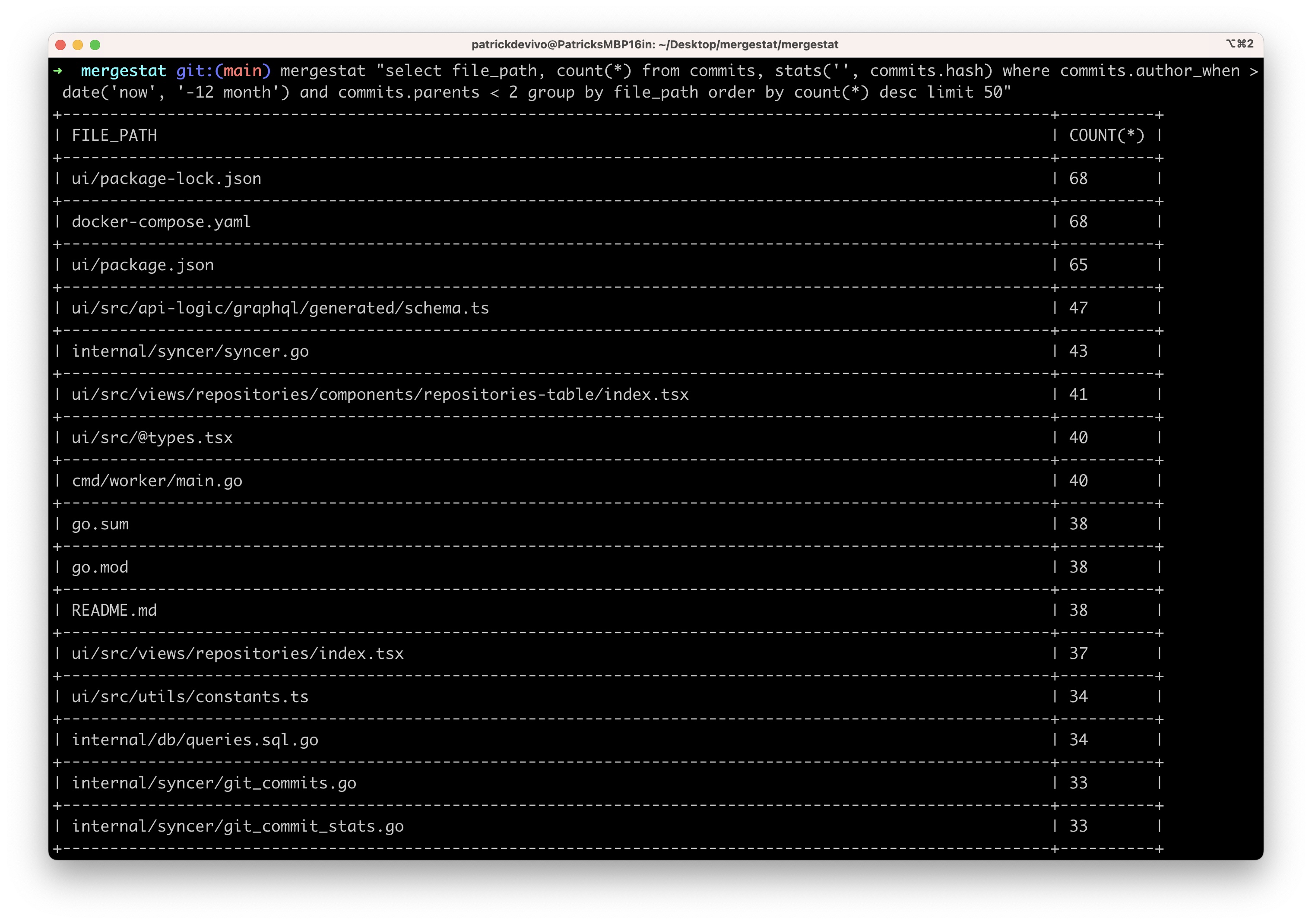
Today we're very happy to announce a new flavor of MergeStat!
If you've been following our progress over the last year, you'll know that our mission is to enable operational analytics for software engineering teams.
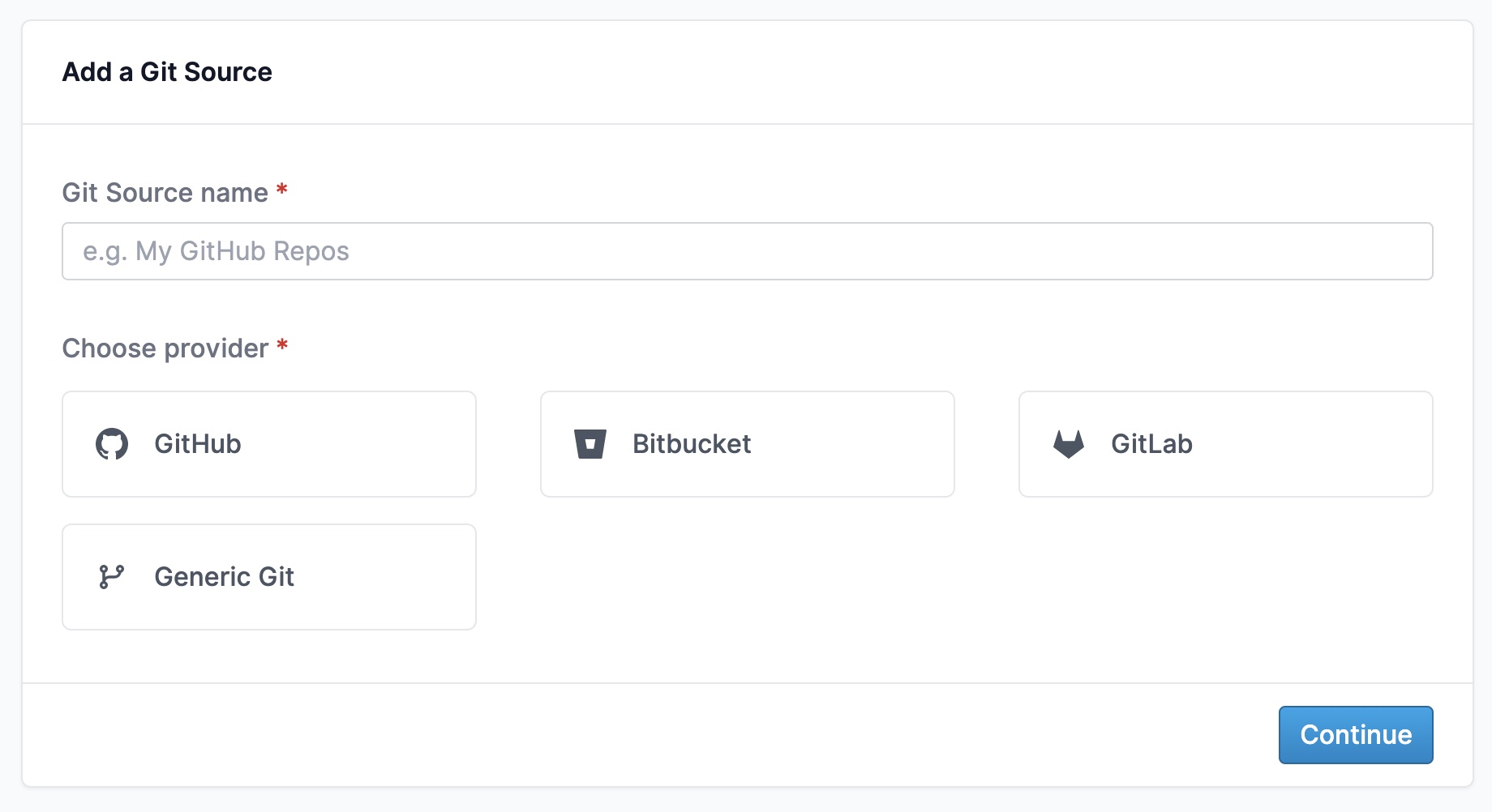
You'll also know that our approach has been heavily based on SQLite (and its virtual table mechanism) to bring data from git repositories (source code, metadata, the GitHub API, etc) into a SQL context for flexible querying and analytics.
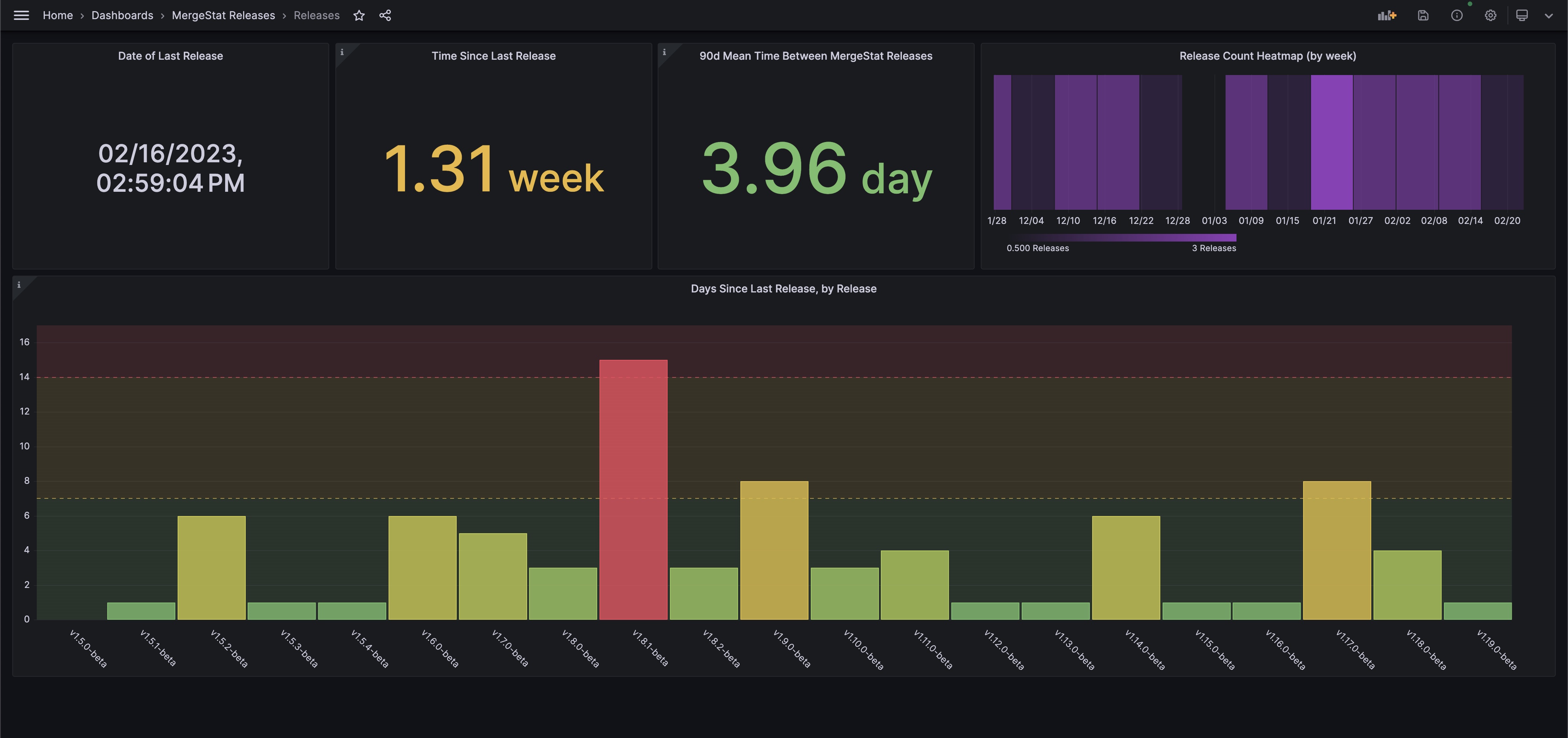
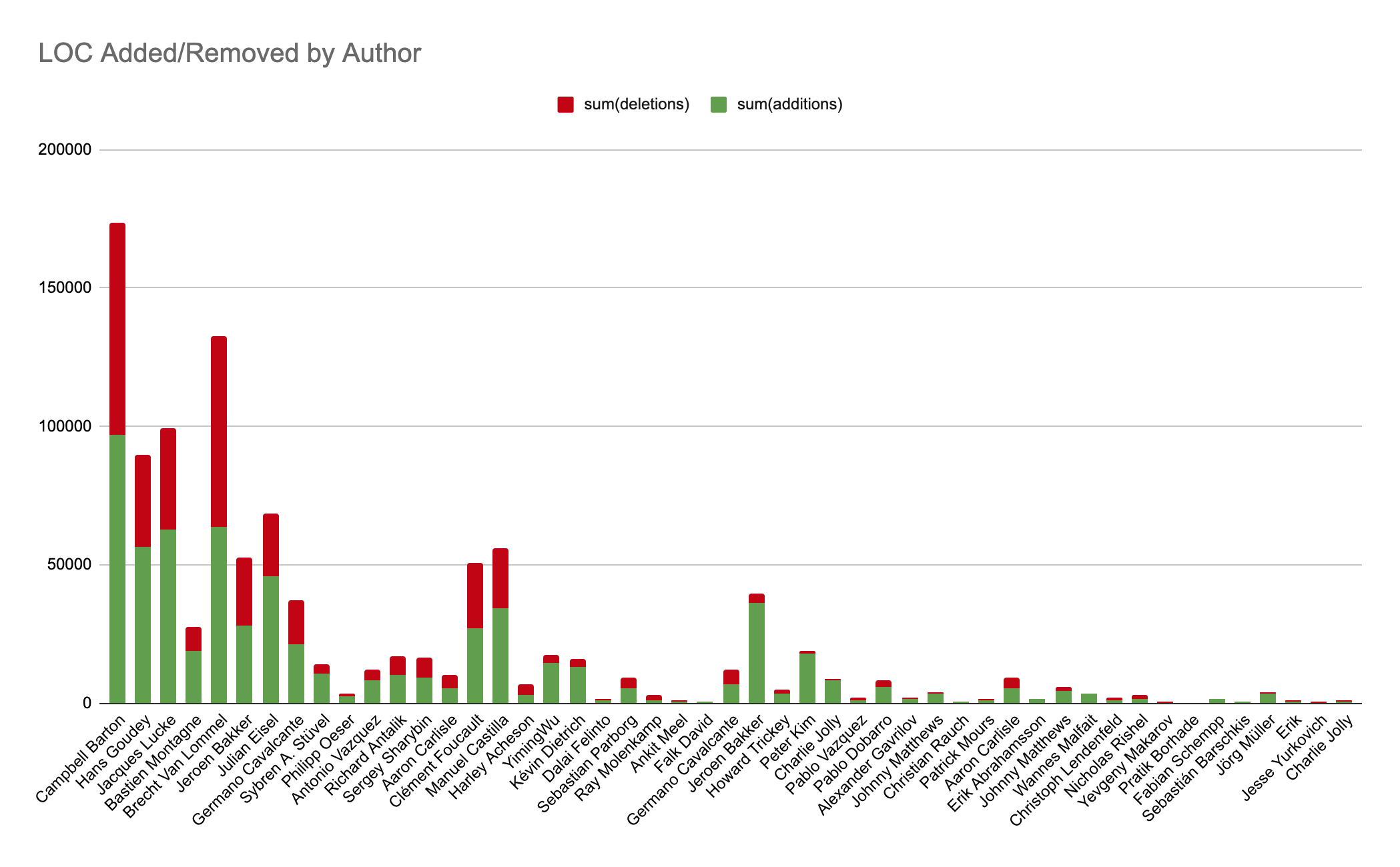
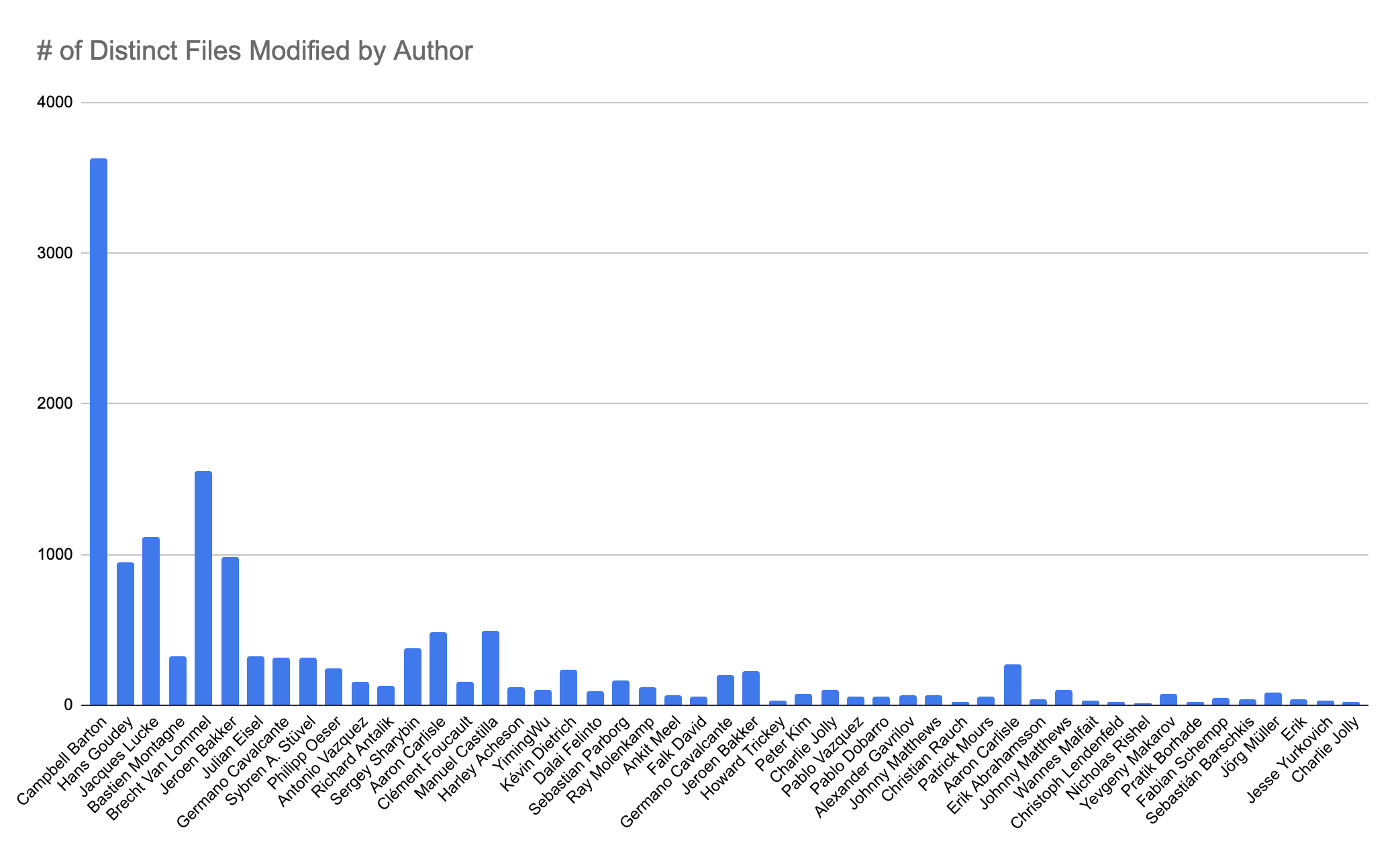
This has enabled initial use cases in many interesting domains related to the software-development-lifecycle, from audit and compliance, to code querying, to release time metrics, to technical debt surfacing, and much, much more.
For the past several months, we’ve been working on an approach in service of this mission that uses a different mechanism for enabling that SQL context.
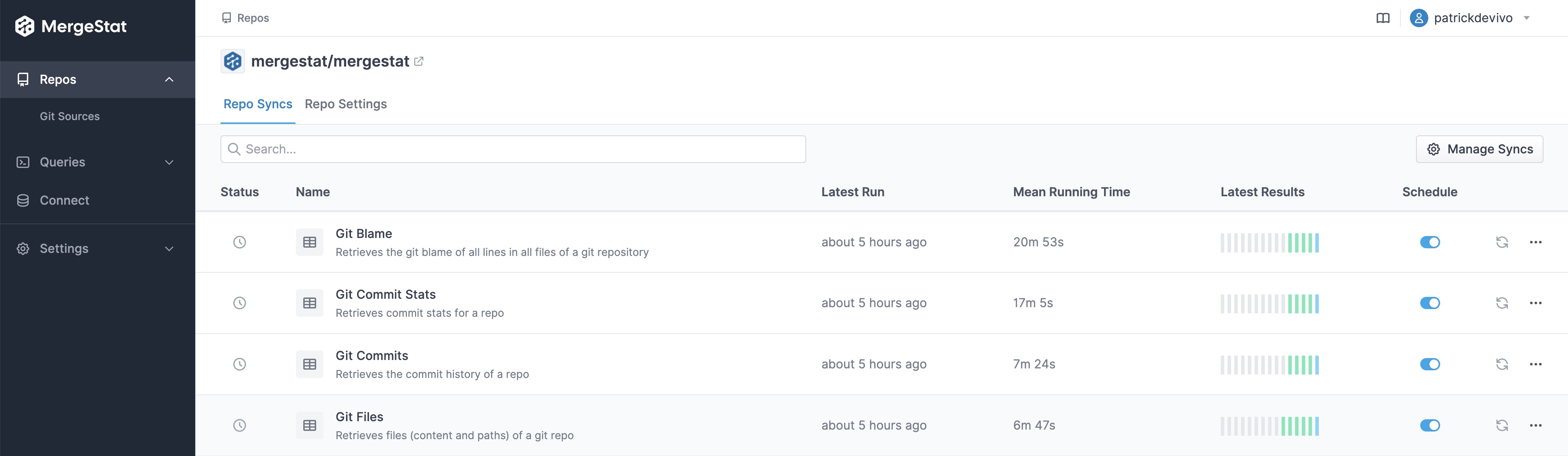
That mechanism is based on syncing data into a Postgres database for downstream querying, vs using a local SQLite based approach.
This grants us two significant advantages:
- More compatibility with the ecosystem of data (and BI/visualization) tools
- Much faster query time for data spread across multiple API sources
More Compatibility
We love SQLite, but the fact of the matter is that it’s much easier to integrate a data visualization or BI product (open-source or not) with a Postgres server (or Postgres compatible server) than with a SQLite database file.
A central part of our mission has always been not just enabling SQL, but allowing our SQL solution to play well with the wide array of existing tools that companies, teams and individuals are already using.
We want anyone to be able to query MergeStat data from tools like Metabase, Grafana, Tableau, Superset, etc. Postgres compatibility takes us a step in that direction, and we’re already working with early users integrating their SDLC data with these types of tools, via MergeStat.
Faster Queries
Our SQLite virtual-table based approach is an effective way to query a local data source (such as a git repository on disk). However, it begins to fall short when it comes to querying over large sets of data spread across many pages in a web API (or multiple APIs). What ends up happening is queries spend much more time waiting for HTTP requests to finish than actually executing SQL. This means at query time, the user is forced to wait for data collection to occur. Depending on the scope of the data involved, this can potentially take a very long time. With our new approach, data is synced and maintained in a background process, so that data collection (from potentially slow sources) occurs out-of-band from user queries.
What’s Next?
Our SQLite approach isn’t going anywhere. We still intend to invest in that and continue building it into a valuable open-source CLI that anyone can use. It’s been renamed MergeStat Lite and now lives at mergestat/mergestat-lite.
Our new approach now lives at mergestat/mergestat.
Our documentation has been updated to reflect these changes, and we couldn’t be more excited to share more in the coming days and weeks.
We have some great features planned, and will be spending more time showcasing various use-cases from our growing community.
As usual, our community Slack is a great place to find help and ask questions. We're always happy to chat about MergeStat there 🎉!